
TL;DR: During a break from client work, I decided to go hard into AI and open source everything. No title, no marketing, just building. As the stars and forks accumulated, I started noticing something: people didn’t care who I was. They cared whether the work solved their problem. By the time I reached the top 0.01%1 of GitHub, I’d discovered something important: work counts. This wasn’t a planned experiment. It was a discovery that unfolded as I participated.
I Was Just Doing the Work
On September 11, 2024, during a break from client and leadership work, I made a commit to a public repository. Not with titles. Not with my professional identity. Just as vanzan01, a GitHub handle nobody knew.
I’d been working with AI since 2017: side projects, private repos, learning by doing. (The full journey is in The Side Hustle That Mattered.) But this was different. This was public. Open source. Out there for anyone to see, use, and judge.
I wasn’t testing a hypothesis. I was just doing the work.
And since I’d spent my entire career in the private and enterprise space (where we don’t share anything, where we’re afraid of people stealing our ideas), I wanted to experience the open source world.
Let the world have it. Let them build on it.
No resume. No network. No title. Just code.
What I didn’t expect was what happened next.
The First Project: Memory Bank
I was building tools to solve my own problems. Context amnesia in AI: the frustration of re-explaining architecture to Claude every session. LLMs forgetting your patterns mid-conversation. The industry was “prompting” like we were summoning genies from bottles. Where was the engineering discipline?
I saw a gist talking about a “memory bank” concept used in Cline. That got me thinking: I could use Cursor rules and add my own twist to it. My twist was the engineering patterns and prompts, structured as a graph, with the hope that the agent would progressively disclose parts of information as needed.
Notice that phrase: progressively disclose. That’s now how skills work in Claude Code. Not in a graph like I did, but the agents are trained to look for context and drill down further. I didn’t have that back then. I just hoped a graph structure would suffice.
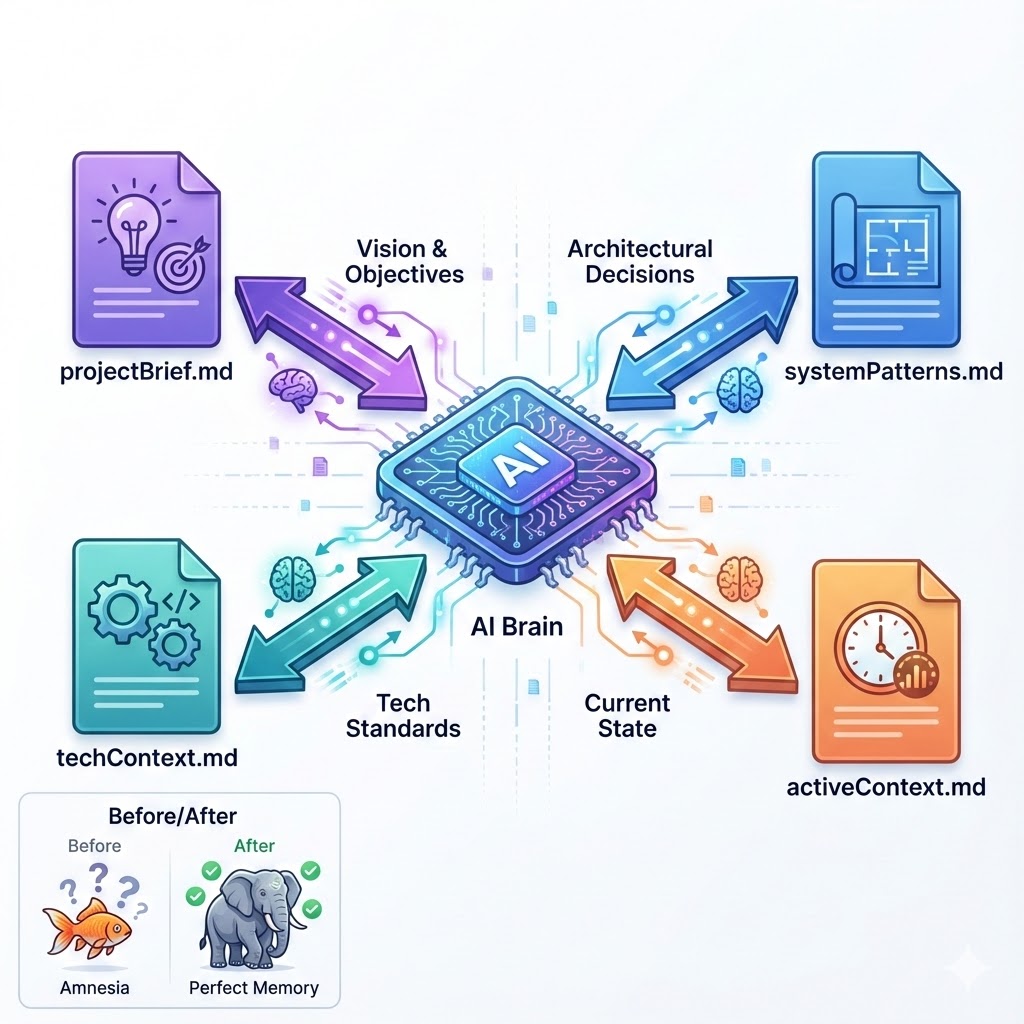
The result was a structured documentation system that gave AI actual “memory”:
projectBrief.md- The vision and objectivessystemPatterns.md- Architectural decisions and why they were madetechContext.md- Technology conventions and standardsactiveContext.md- Current state and recent changes
Would you hire a developer who forgot your entire codebase between meetings? No? Then why were we accepting that behaviour from AI?
I wasn’t building for fame. I was building because I needed it.
Then Something Happened
The stars started coming in. First dozens. Then hundreds. Then thousands.
At first, I didn’t think much of it. People star things all the time. But then came the forks. Over 400 of them.
Here’s why that matters: stars are passive, a bookmark, a “looks interesting.” Forks are active: someone copying your code to build on it. That’s not passive interest. That’s people actually building with it.
And here’s the thing: they had no idea who I was.
That’s when the question started forming in my mind:
Are people really after actions and results rather than potential and perceived capability?
The more I watched, the more I realised this was an answer unfolding in real time.
How It Spread
I wasn’t marketing. I was just helping people.
Someone would have a problem. They’d find the repo, use it, and it would solve their problem. Then they’d share it with others. Completely organic. Word of mouth.
Then it started appearing on X. People I’d never spoken to were recommending my repo. Some were entrepreneurs. Some were developers at startups. And then I noticed something that stopped me cold: product managers and engineering leads at large tech companies were sharing it personally, tweeting about how they were using it to accelerate their own work.
Out of the blue, I got an email from an influencer. He wanted to do an interview, show his audience how to use the tool. I declined. I wanted to keep it under the handle. But I helped him understand the repo, walked him through how it worked.
He talked about it anyway. Then two or three other influencers picked it up. More videos. More shares. More people finding it.
My architecture was even presented at the AI Coding Dojo meetups in Japan. Enterprise developers learning patterns I’d developed while working under a handle on the other side of the world.
All of this, completely organic. No marketing budget. No promotional campaign. Just people finding something useful and telling others about it.
You can see the trail yourself: search “vanzan01” on X. Hundreds of mentions. All word of mouth.
That’s when I really started to understand: work that solves real problems spreads on its own.
Pushing Further
Once I noticed the pattern, I leaned in.
What would happen if I kept going? No marketing. No name recognition. No conference talks. Just pure engineering at the cutting edge, fully open sourced.
I wanted to see how far work alone could take you.
So I kept building:
The VAN/PLAN/CREATIVE Lifecycle
I created a state machine for development that treated AI collaboration like actual software engineering:
- VAN Mode: Structured ambiguous requirements into clear specifications
- PLAN Mode: Designed the architecture before writing code
- CREATIVE Mode: Implemented with full context awareness
- ARCHIVE: Preserved the thinking process for future reference
This wasn’t revolutionary rocket science. This was basic engineering discipline applied to a new problem space. But apparently, that made it revolutionary.
JIT Rule Loading
This is where my thinking around context engineering really started to take shape.
I called it “JIT Rule Loading” at the time: Just-In-Time context loading. The idea was simple: only show the AI the rules it needed for its current phase. Don’t dump everything on it at once.
I’d been debugging a Claude session for three hours when I realised the problem: the AI was tripping over conflicting instructions from different development phases. Rules meant for planning were interfering with implementation.
The solution felt obvious once I saw it: scope the context. Load what’s needed, when it’s needed.
What I noticed:
- Fewer tokens wasted on irrelevant context
- Less “context drift” where the AI would lose track
- More consistent behaviour across sessions
The Claude Code Collective
When Claude Code came out, it gave me more direct access to the model than Cursor’s abstractions did. That opened up new possibilities.
I decided to try defining agents with prompts. This was before sub-agents even existed as a concept. I was essentially trying to simulate multi-agent behaviour through careful prompt engineering. When sub-agents eventually came out, I adapted to use them.
But even with sub-agents, the system still wasn’t deterministic enough for my liking. So I added Taskmaster to handle project management, then trained an agent to use it through prompts. I also started using hooks to report and validate things along the way, trying to add some accountability to the process.
The outcome surprised me. Users were running this system non-stop for well over 8 hours. At the time, that was a real achievement: one of the first very long-running agentic systems I’d seen actually hold together.
The Results That Kept Coming
All of this, under a handle.
GitHub Metrics
- Almost 3,000 stars: top 0.01% of all repositories globally1
- Over 400 forks: a 15% fork ratio (3x the industry average for complex systems)
- International adoption: Japan, China, US, global developer communities
That 15% fork ratio puts it in the same league as framework giants like Vue.js (~16%) and React (~21%). People weren’t just starring and moving on. They were building with it.
I reached the top 0.01% of GitHub1 under a handle.
The Shadow Footprint
Beyond the visible GitHub metrics, my work lives in places I’ll never see:
- Private enterprise stacks: some of those forks are running in places I’ll never know about
- AI coding bootcamps: teaching Context Engineering as core curriculum
- Derivative tools: MCP servers and frameworks built on my structure
- Community standards: VAN/PLAN pattern copied everywhere
This is the shadow footprint every open source maintainer dreams about: your work solving problems you’ll never hear about, in companies you’ll never meet, for developers who’ll never know your name.
Except now they will.

What I Discovered
This wasn’t a controlled experiment. It was a discovery that unfolded as I participated.
Here’s what I found:
1. Work Counts
Not credentials. Not connections. Not perceived potential. Work.
When you build something that solves a real problem, people find it. They use it. They fork it. They build on it. They don’t care who you are. They care whether it works.
Almost 3,000 stars came from the fitness of the architecture, not from my resume.
2. Working on Hard Problems Counts
I could have built simple tools. Quick wins. Things that would get stars but not solve anything deep.
Instead, I tackled context amnesia, a problem everyone was experiencing but few were engineering solutions for. I was engineering the environment while others were still in the “magic prompt” era.
The hard problems attracted the serious users. The 400+ forks represent teams who needed real solutions, not toys.
3. Working at the Cutting Edge Counts
I was there when MCP launched. When Claude Code came out. When sub-agents became possible. At each step, I adopted, learned, built, shared.
Being at the frontier means your solutions are fresh. Relevant. Needed.
And here’s the thing about frontier work: even when you know frontier labs will eventually solve the same problems, your participation matters. The learning, the debugging at 2 AM, the dead ends: that’s the point. Being handed a solution at the end without putting in that effort? To me, at least, it doesn’t feel as fruitful.
You have to participate. That’s the lesson.
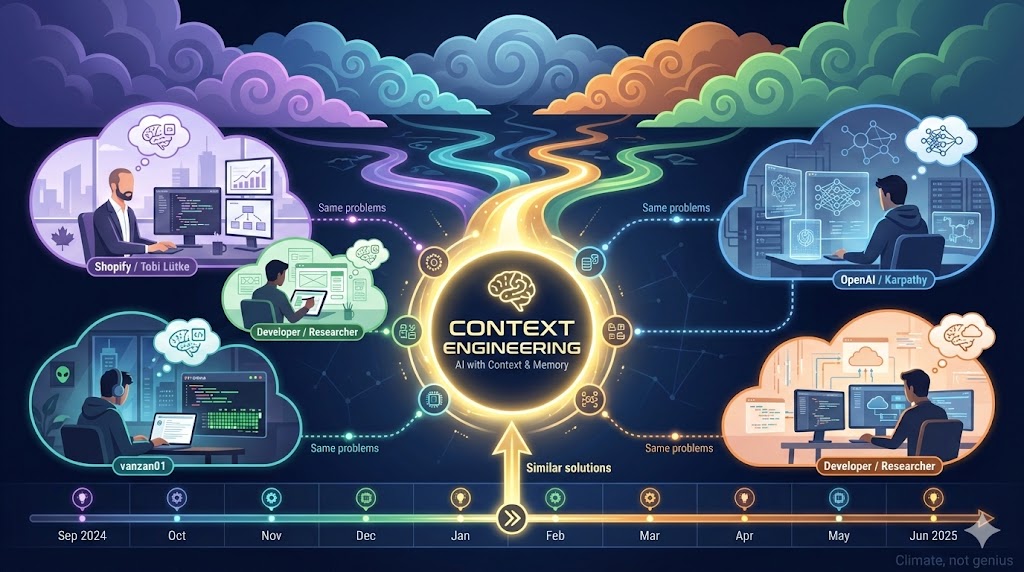
4. Ideas Emerge From Climate, Not Genius
In June 2025, Tobi Lütke (Shopify CEO) and Andrej Karpathy (ex-OpenAI) popularised the term “Context Engineering.” I’d been working on these same problems since September 2024, thinking through context, documentation, and AI reliability.
But here’s the thing: I don’t claim to have “invented” it.
Great ideas don’t come from lone geniuses working in isolation. They emerge when the intellectual climate reaches a boiling point. When the problem becomes acute enough, multiple people arrive at similar solutions independently.
What matters isn’t who thought of it first. What matters is that you were there, thinking through the same problems, putting in the work.
I was there. I spent hours testing, millions of tokens that could have been spent building apps. But I needed a foundation I was comfortable with. And honestly? Even today, I’m still not comfortable. While everyone claims AI can do everything, the deep work reveals pitfalls that only become obvious with time and use.
Why I’m Sharing Now
This isn’t about claiming glory or seeking validation.
It’s about three things:
1. Sharing What I Learned
The discovery was too important to keep to myself: work counts, credentials don’t. At least not in open source.
If you’re building something valuable, people will find it. They’ll use it. They’ll build on it. Your title doesn’t matter. Your output does.
2. Inspiring Others
You don’t need permission to move an industry forward. You don’t need a title, a PhD, or funding from a VC firm.
You need:
- A problem that’s acute enough
- A solution that actually works
- The rigour to prove it works at scale
- The courage to ship it
The big question isn’t whether you have the credentials. It’s whether you have the problem-solving discipline to make a difference.
3. Recognition of Participation
I helped think through the same problems everyone else was facing. I spent the time testing and iterating when I could have been building apps, because I needed a foundation I understood deeply.
I was part of the thinking that shaped how we work with AI today. And that participation has value, even if frontier labs were working on the same problems.
Looking Forward
The approaches I worked on have evolved:
- JIT Rule Loading → Replaced by skills and progressive disclosure in modern CLIs and IDEs
- Memory Banks → Still unsolved until models can continuously learn, but we have workarounds
- Multi-Agent Systems → We’re seeing deployment now. Scale will be the key.
We’re not just improving how we code with AI. We’re engineering entirely new paradigms for human-AI collaboration.
I’m Nick. CTO and AI architect. I build as vanzan01.
The handle stays. It proved something too important to retire.
The Discovery
I didn’t set out to prove anything. I set out to build.
But along the way, I discovered something I’d suspected but never tested:
You don’t need permission to make a difference. You need dedication, and you need to participate.
The discovery validated this through results I never expected, all purely through the fitness of the work itself.
Where does that leave you?
Connect With Me
Want to dive deeper into Context Engineering or discuss how these patterns can transform your AI development workflow?
- GitHub: github.com/vanzan01
Acknowledgments
To everyone who:
- Forked cursor-memory-bank and built production systems on it
- Presented my work at conferences and taught it to your teams
- Cited my architecture in blogs, editorials, and internal documentation
- Adopted Context Engineering as a discipline in your organisations
Thank you for being part of the discovery.
We didn’t just survive the “Prompting Era”. We engineered our way out of it.
Published: January 7, 2026 Author: Nick (vanzan01) Location: Perth, Australia
What’s your experience building in public? Have you found that work speaks louder than credentials? Let’s discuss.
Footnotes
-
Based on 420M+ total repositories (GitHub Innovation Graph, Q3 2025) vs ~19.5k repos with >3k stars. Actual rank: top 0.005%, conservatively rounded. ↩ ↩2 ↩3